quanteda
Information
- Documentation: https://kbenoit.github.io/quanteda/
- Github organization: http://github.org/kbenoit/quanteda
- Docathon project: https://github.com/kbenoit/quanteda/projects/3
Description
quanteda is a fast, flexible toolset for for the management, processing, and quantitative analysis of textual data in R. It includes functions for exploring text, tokenizing texts, managing corpora and associated meta-data, creating document-feature matrixes, computing a variety of text-based statistics, plotting textual representations, computing statistical and machine learning models on texts, applying dictionaries to texts, detecting collocations, and more.
Open Doc issues
- Create standard texts and a dictionary for examples
- create a cheatsheet
- Improve quanteda.io website
- How to left join docvars with those in an existing corpus
- inconsistent output between topfeatures and docfreq
- Wishlist: more documentation / vignettes for textmodels
- topfeatures per-document option
- Document C++ functions, remove those unneeded
- docfreq man page needs clarifying equation(s)
- Complete Jockers vignette
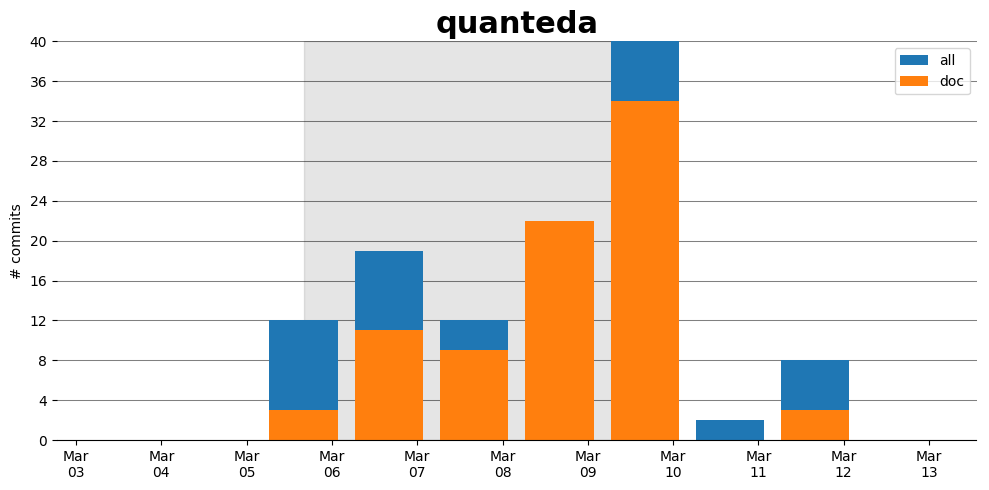
Activity